Introduction to Web Scraping with Python
Prerequisites
Although this guide will use mostly basic Python and HTML, because they are very beginner-friendly languages that resembles English, there is really no need to know anything about these languages. However, for the final part, you do need to understand basic CSS, and if you don't, feel free to skip it. Anyways, without further ado, let's started!
What is Web Scraping?
Just like how it sounds, web scraping is a method of extracting data from a website, where the scraped data would then be saved into a tabular (spreadsheet) format, often for further work to be done on it. Website data often contains valuable information and I think it's great for everyone to know at least the basics of web scraping to benefit from it.
Getting Started
A great way to immediately start web scraping is using Google Colab as our environment. All you need is literally a google account where you can sign into to create a new Colab notebook. Once the notebook is open, we can start writing and executing Python code.
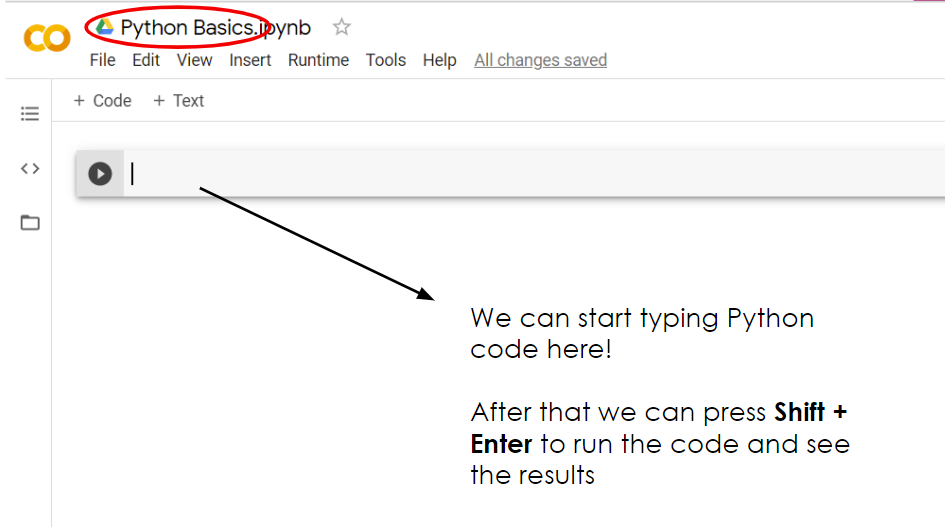
Installing Beautiful Soup
An easy way to scrape data using Python is using a package or library called Beautiful Soup. Let's do a pip install and import it like so:
!pip install beautifulsoup4
from bs4 import BeautifulSoup as bs
Note: In Google Colab, we can run a console command by starting with a ! followed by the command.
Now, we'll want to choose a website that we want to scrape data from. For illustration purposes, I'll choose this website: https://pokemondb.net/pokedex/all, just because I like Pokémon and it seems like an ideal table of data to scrape from. At this point, we want to get the HTML for this website, and we can do that through a simple GET request using the requests library. Again, let's do a pip install and import it.
!pip install requests
import requests
res = requests.get("https://pokemondb.net/pokedex/all")
Then, simply convert our HTML content to a beautiful soup object.
soup = bs(res.content)
We can see the whole HTML document by printing it out like so:
# prettify is a function that returns a nicely formatted HTML with newlines and indent
# that makes it easier to read
print(soup.prettify())
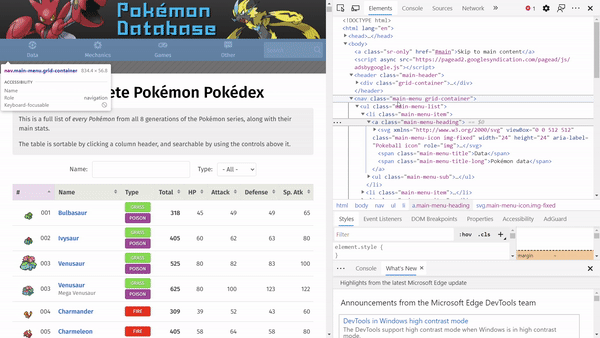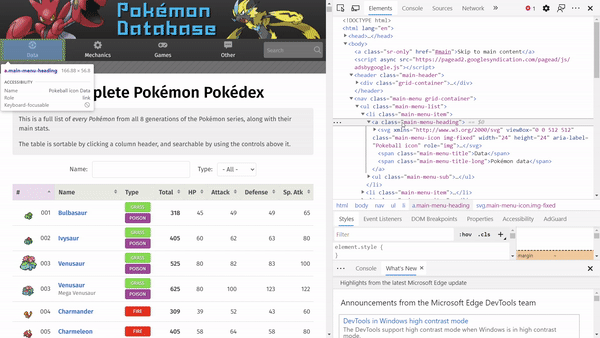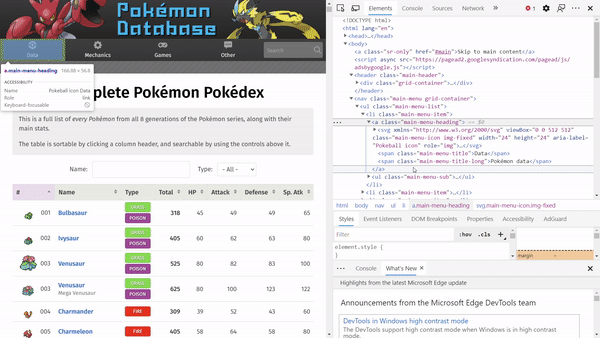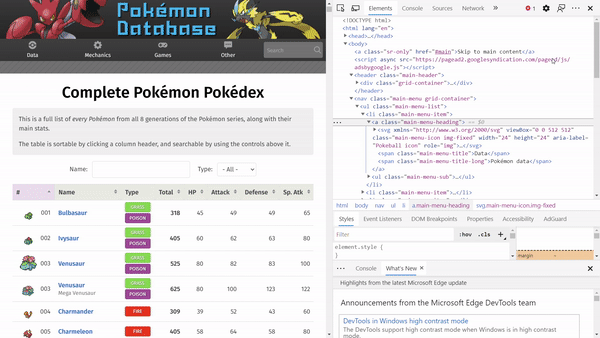
Taking a look at our HTML, we can see many HTML elements (i.e., the words that are enclosed in angular brackets, where the first word is the element name). For example, in the following HTML snippet, we have a nav, ul, li, a, svg, and span element.

To see how each HTML element looks like on the website, navigate to the website, right-click and click inspect. Hovering each element, we can see parts of the website being highlighted.
Searching the Soup
To search for a specific HTML elements that we want to extract data from, there are mainly two functions to choose from: find() and find_all(). Both functions accept a filter argument that pinpoints the element you're looking for. The filter argument can be one of the following types:
1. String
Say from our HTML snippet, we want to get our first span element, we can use the find method like so:
soup.find('span')
# Output: <span class="main-menu-title">Data</span>
Alternatively, if we want to get all span elements, we can use the find_all method like so:
soup.find_all('span')
# Returns a list of all span elements
However, this is not really how you want to scrape data as span elements are HTML elements that inherently don't mean anything. You can see a short description of what each HTML element represent here
The HTML <span> element is a generic inline container for phrasing content, which does not inherently represent anything. It can be used to group elements for styling purposes (using the class or id attributes), or because they share attribute values, such as lang.
2. Regex (Regular Expressions)
We can also pass in a regex to search for our desired HTML element. The following example shows how we can find elements with strings that contain "sceptile" or "Sceptile".
import re # import regex
soup.find_all("a", string=re.compile("(s|S)ceptile"))
3. List
Oftentimes, we would want to find more than one type of HTML element. Well, it is as simple as passing a list of strings instead:
soup.find_all(['a', 'li'])
4. A Function
For more flexibility that three of the above following methods, we can pass a custom function that we define that returns a boolean according to whether the element matches our search criteria.
def has_class_but_no_id(tag):
return tag.has_attr('class') and not tag.has_attr('id')
soup.find_all(has_class_but_no_id)
#5. Keywords Say we want to filter by HTML elements that have a specific attribute like href (i.e., has a link). We can do this by passing the href keyword argument:
# find elements that has a href attribute
soup.find_all(href=True)
# find elements with a href attribute and the link contains the string "sceptile"
soup.find_all(href=re.compile("sceptile"))
Navigating the Soup
We've seen how to pick out elements based on certain criteria we're looking for but sometimes, you just want to navigate the soup object in some orderly manner, and there are essentially 3 different directions to go about: top-down (i.e., parent to children, descendants), bottom-up (child-to-parent(s)), side-to-side (i.e., within siblings and within elements).
Parent-to-Children
.contents
- returns a list of the element's direct children
.children
- returns a list iterator of all direct children, which can be iterated using the for loop
Descendants
.descendants
- returns a generator object of all descendants of the element, which can be iterated using the for loop
Child-to-Parent(s)
.parent
- returns the direct parent of the element
.parents
- returns a generator object of all ancestors of the element, which can be iterated using the for loop
Within Siblings
Siblings are elements that are nested within the same level.
.next_sibling
- returns the next element (i.e., element below) that is on the same level as the current element
.previous_sibling
- returns the previous element (i.e., element above) that is on the same level as the current element
.next_siblings
- returns a generator object of all next siblings (i.e., siblings below the element), which can be iterated using the for loop
.previous_siblings
- returns a generator object of all previous siblings (i.e., siblings above the element), which can be iterated using the for loop
Within Elements
.next_element
- returns whatever is immediately parsed afterwards
Example:
soup.find('span')
# Output: <span class="main-menu-title">Data</span>
soup.find('span').next
# Output: 'Data'
.previous_element
- returns whatever is immediately parsed before the element
.next_elements
- returns a generator object containing next elements, which can be iterated using the for loop
.previous_elements
- returns a generator object containing previous elements, which can be iterated using the for loop
Note: Iterators and generators can be converted to lists using the list() function in Python
Using CSS Selectors
And finally, Beautiful Soup supports searching HTML elements using its select() method which accepts a CSS selector as an argument and returns all matching elements. A few examples:
# find a's that are inside div's
soup.select("div a")
# get direct descendants of div's that are a's
soup.select("div > a")
# get the element with id = pokedex
soup.select("#pokedex")
Now that we know the basics of how to pick out and navigate through the soup, let's attempt to do a full scraping of the table of data on the website. If we inspect it, we can see that it has an id = pokedex and ignoring the header row, the rows of data we want to extract is the 4th child (i.e., tbody). Notice how the newlines separating each elements are considered children.
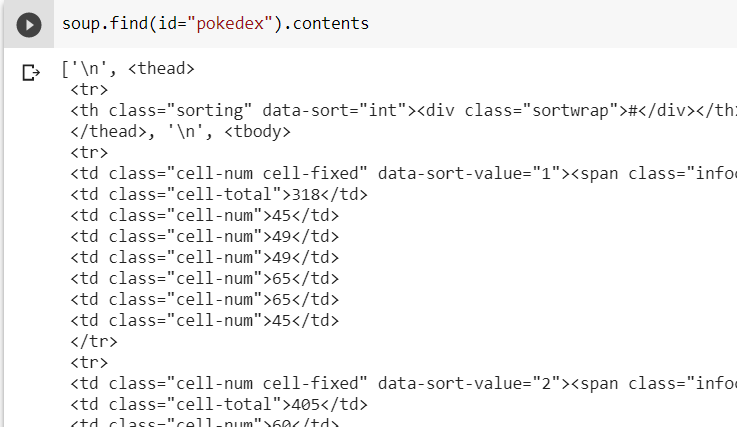
Printing out the 4th child, we can see that we have retrieved the table that we want.
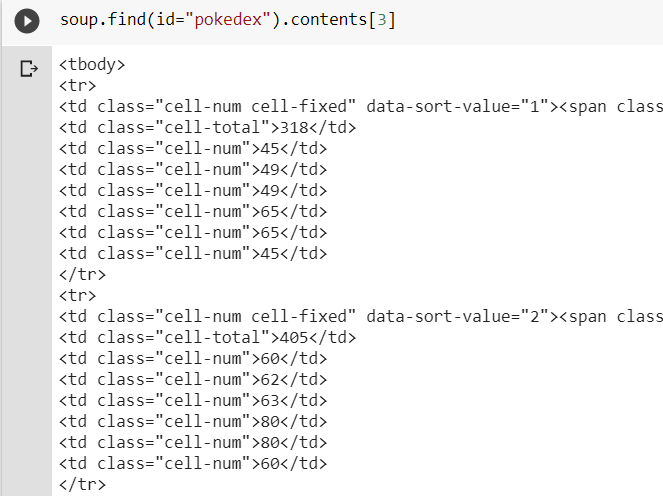
Now, we want to iterate through its direct children and for each of the direct children, we want their children, but just the strings in them and we can use a 2D list to represent this table in Python. The direct children being the outer list (i.e., columns) and the children of the direct children being the inner list (i.e., rows). To get the string beneath a HTML element, we can use the get_text() method.
col = []
for direct_children in list(table.contents):
row = []
if direct_children != '\n':
for child in direct_children.find_all("td"):
row.append(child.get_text())
col.append(row)
Printing the variable, col, out, we can see that we have successfully extracted the table of data!

Now, let's save this to a csv file named PokeStats:
import csv
with open("PokeStats.csv", "w", newline="") as f:
writer = csv.writer(f)
writer.writerows(col)
In Google Colab, if you navigate to 'Files' on the drawer to the left, you'll see newly created csv file there.
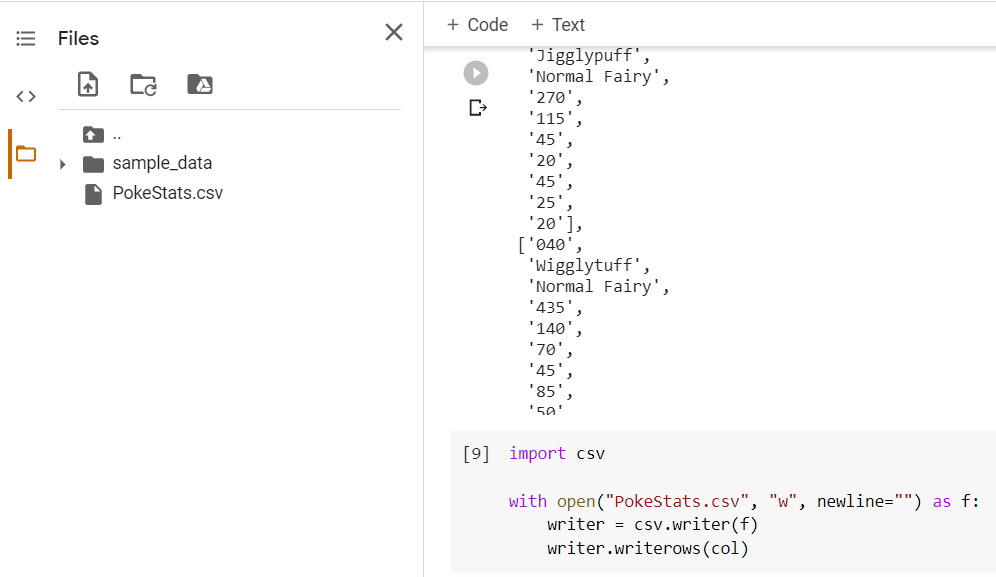
Simply download it and we'll see our nicely extracted data in excel!
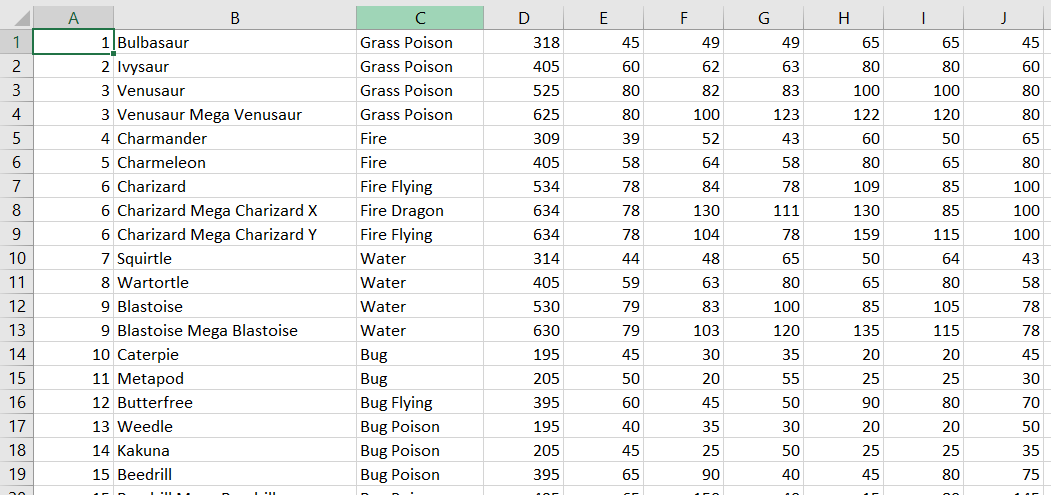
Hopefully, this was helpful. Thanks for reading!




