


Why a Recommendation Engine?
As a developer who barely knows anything about ML (machine learning), I find building a recommendation engine one of the easiest projects to get started with ML. It is practical and not that difficult to understand for beginners with no machine learning background to jump right into.
Getting Started
Before we get started with the actual implementation, I'll brief some concepts that you might find helpful to build a recommendation engine.
There are essentially 3 types of algorithm that your recommendation engine could use when recommending an item to a user:
1. Demographic Filtering
This type of filtering looks at the general trends and popularity of an item based on users with similar demographics. This means that users with similar demographics are recommended the same items and personalized recommendations are very limited.
2. Content-Based Filtering
The underlying algorithm for this type of filtering looks at the similarity of items based on its metadata. For example, for games, the metadata would be things like platforms, genres, and publisher. Therefore, if a user liked a PC action RPG game that is published by Valve, then most likely he or she would like another game that has similar metadata (i.e., games that are published by Valve and are action RPG PC games). This means that personalized recommendations are now involved, since games that the user liked is used to determine games that the user probably like too.
3. Collaborative Filtering
The final type of filtering can be broken to two types.
- User-based: matches users to items based on other users. Specifically, other users that are determined to be similar to the user by the algorithm. This means given a user and another user that is found to be similar to the user, what the other user liked is recommended to the user.
- Item-based: matches users to items based on items' similarity with items that the user has rated. This means if a user liked item X, and item X is found to be highly similar to item Y, then item Y will be recommended to the user.
The best type of recommendation engine would obviously integrate all 3 types but in this tutorial, we'll focus on the last type: collaborative filtering, since it is arguably the strongest type.
Matrix Factorization
A class of collaborative filtering algorithm that we'll be looking at is called Matrix Factorization. The end goal of matrix factorization is basically to build a matrix of users and items filled with known and predicted ratings.
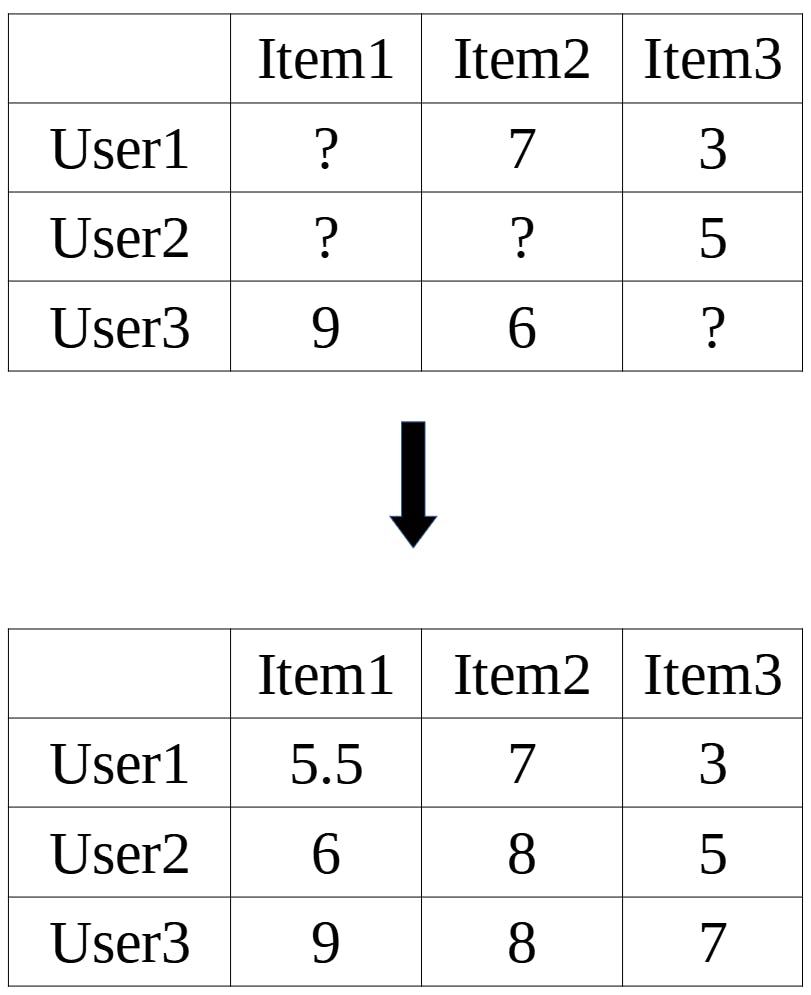
Starting with our original matrix of only known ratings, we want to determine the two factor matrices that would produce our original matrix. These two matrices would in turn represent information of the users, items, and the relationships between them. One being the matrix that quantitatively represent the users (user matrix) where each row of the matrix is a vector of size k that represents a single user, and the other being the item matrix, where each column of the is a vector of size k that represents a single item.
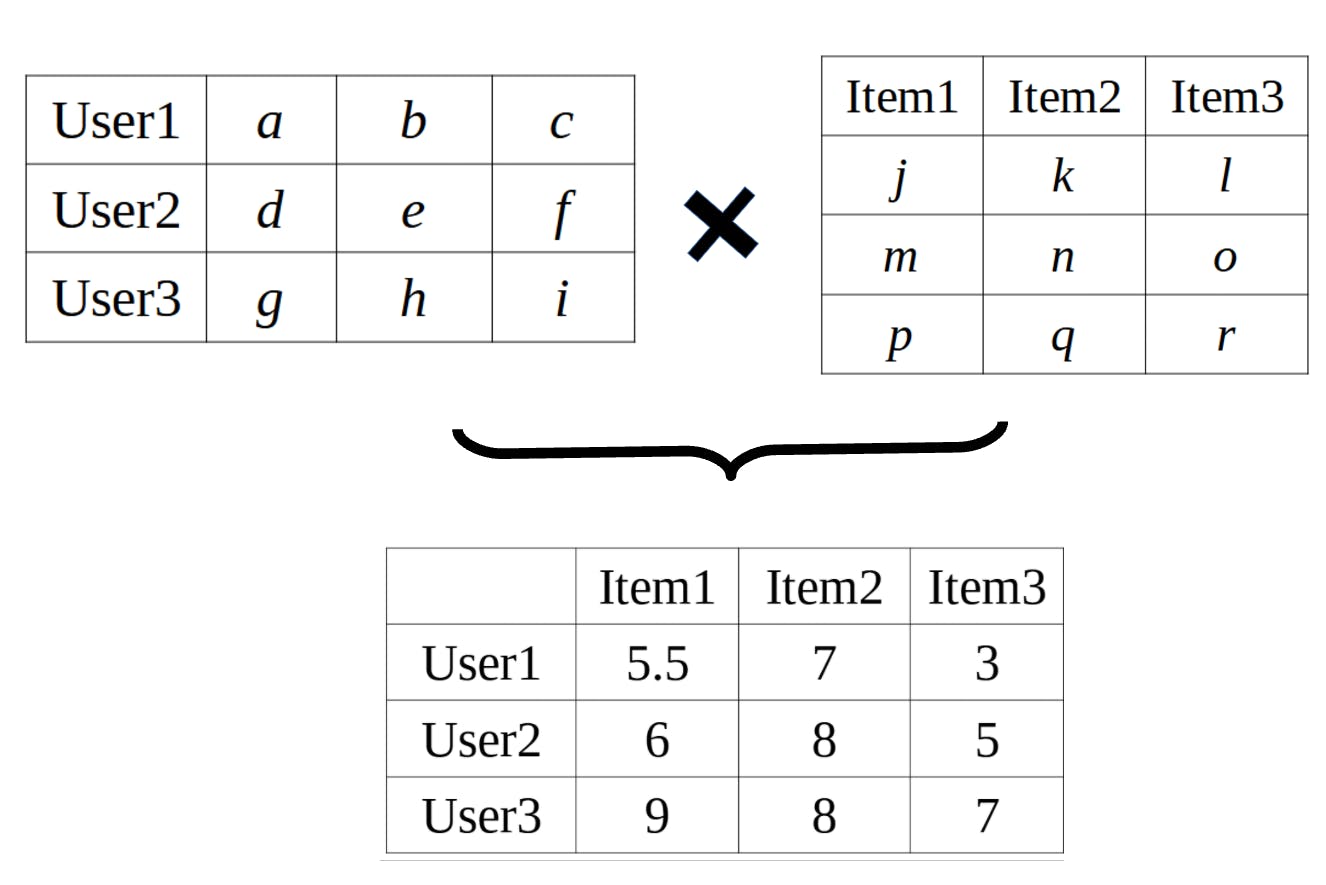
k is called the embedding size and is a hyperparameter that is tuned in the matrix factorization model. A larger embedding size would allow for the model to capture more complex relationships and information, but may lead to overfitting.
Matrix Factorization Model in PyTorch
Taking the idea of Matrix Factorization, let's implement this in PyTorch.
First, let's import some necessary modules.
import torch
import torch.nn as nn
import torch.nn.functional as F
from sklearn.model_selection import train_test_split
Next, let's build our Matrix Factorization Model class.
class MF(nn.Module):
def __init__(self, num_users, num_items, emb_size=100):
super(MF, self).__init__()
self.user_emb = nn.Embedding(num_users, emb_size)
self.item_emb = nn.Embedding(num_items, emb_size)
# initializing our matrices with a positive number generally will yield better results
self.user_emb.weight.data.uniform_(0, 0.5)
self.item_emb.weight.data.uniform_(0, 0.5)
def forward(self, u, v):
u = self.user_emb(u)
v = self.item_emb(v)
return (u*v).sum(1) # taking the dot product
To instantiate our model, we can simply call on it like so:
model = MF(num_users, num_items, emb_size=100)
Where num_users represent the number of unique users and num_items represent the number of unique items in the dataset.
For illustration purposes, here is a sample dataset that I'm using:
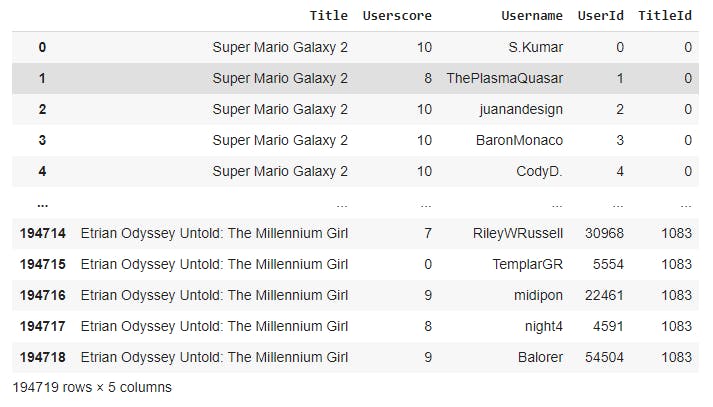
The items here are games that we want to recommend to users.
Once the model is instantiated, we can proceed to split our dataset to train and test our model. The general split is 20% test and 80% training.
train_df, valid_df = train_test_split(dataset, test_size=0.2)
# resetting indices to avoid indexing errors
train_df = train_df.reset_index(drop=True)
test_df = valid_df.reset_index(drop=True)
Now, we want to create our training function to train the model.
def train_epocs(model, epochs=10, lr=0.01, wd=0.0):
optimizer = torch.optim.Adam(model.parameters(), lr=lr, weight_decay=wd)
model.train()
for i in range(epochs):
usernames = torch.LongTensor(train_df.UserId.values)
game_titles = torch.LongTensor(train_df.TitleId.values)
ratings = torch.FloatTensor(train_df.Userscore.values)
y_hat = model(usernames, game_titles)
loss = F.mse_loss(y_hat, ratings)
optimizer.zero_grad() # reset gradient
loss.backward()
optimizer.step()
print(loss.item())
test(model)
In each iteration, the training function is basically updating our model to approach a smaller MSE (mean squared error). This is the idea of gradient descent. And finally, our test function, which will be called right after training is done.
def test(model):
model.eval()
usernames = torch.LongTensor(test_df.UserId.values)
game_titles = torch.LongTensor(test_df.TitleId.values)
ratings = torch.FloatTensor(test_df.Userscore.values)
y_hat = model(usernames, game_titles)
loss = F.mse_loss(y_hat, ratings)
print("test loss %.3f " % loss.item())
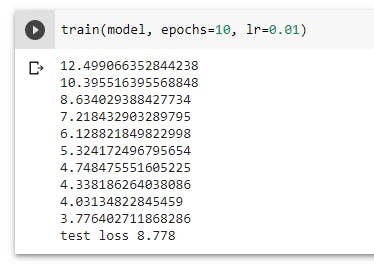
We can see that although our model's lowest MSE in our training dataset was about 3.776, the actual MSE based on our test dataset is about 8.778. Generally, this is a normal result but a big difference between the training and test MSE likely suggests that our model is overfitted.
Model Prediction
And now, we are ready to use our model for prediction! For example, to predict the ratings of games for user of userId 10, we can run the following lines:
user = torch.tensor([10])
games = torch.tensor(game_ratings['TitleId'].unique().tolist())
predictions = model(user_test, game_test).tolist()
print(predictions)
Notice that some of the predictions went over 10. To fix this, we can simply normalize our results like so:
normalized_predictions = [i/max(predictions)*10 for i in predictions]
print(normalized_predictions)
Finally, we can recommend some games by sorting our predictions list:
sortedIndices = predictions.argsort()
recommendations = dataset['Title'].unique()[sortedIndices][:30] # taking top 30
print(recommendations)
Obviously, there are still ways to further improve this model, but I'll leave it here for now. Thanks for reading!